DeepSeek-R1, як і o1, яка тренувалася за методом навчання з підкріпленням (RL), але в DeepSeek говорять, що крім цього застосували контрольоване тонке налаштування, щоб впоратися зі складними завданнями на міркування і відповідати продуктивності o1. Про це повідомляє VentureBeat.
Щоб продемонструвати переваги свого підходу, DeepSeek використовував R1 для дистиляції шести моделей Llama і Qwen, піднявши їх продуктивність на новий рівень. В одному випадку, дистильована версія Qwen-1.5B перевершила набагато більші моделі, GPT-4o і Claude 3.5 Sonnet, в окремих математичних тестах.
Ці моделі, як і основна R1, були розроблені з відкритим вихідним кодом і доступні на Hugging Face за ліцензією Массачусетського технологічного інституту.
Під час тестування DeepSeek-R1 набрала 79,8% на математичних тестах AIME 2024 і 97,3% на тесті MATH-500. Вона також отримала 2 029 балів на Codeforces, перевершивши 96,3% програмістів-людей. В цих тестах версія o1-1217 набрала 79,2%, 96,4% та 96,6% відповідно. В тесті на загальні знання на MMLU, R1 трохи поступилася з точністю 90,8% проти 91,8% в o1.
Ефективність DeepSeek-R1 називають великим досягненням китайського стартапу у сфері ШІ, де наразі переважно домінують компанії з США. Крім того, DeepSeek працює за моделлю open source і відкриває доступ навіть до навчальних матеріалів.
Ще однією перевагою DeepSeek для користувачів є її цінова політика. OpenAI надає доступ до o1 за ціною $15 за мільйон вхідних токенів і $60 за мільйон вихідних токенів. Натомість DeepSeek Reasoner, заснований на моделі R1, коштує $0,55 за мільйон вхідних токенів і $2,19 за мільйон вихідних токенів.
Наразі модель можна протестувати на платформі чату DeepSeek, яка нагадує ChatGPT. Користувачі також можуть отримати доступ до вагових коефіцієнтів моделі та репозиторію коду через Hugging Face, за ліцензією MIT, або скористатися API для прямої інтеграції.
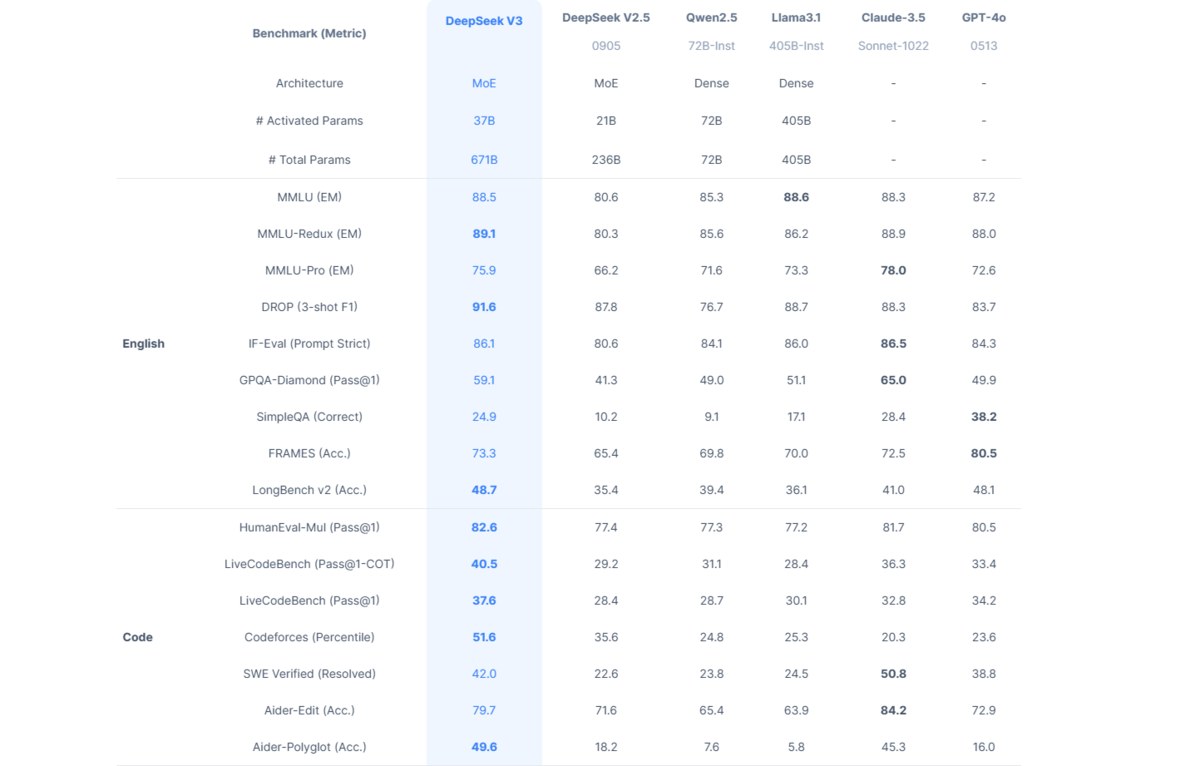
Нагадаємо, що з внутрішнім порівняльним тестуванням DeepSeek, модель DeepSeek V3, на якій базується R1, перевершує як завантажувані, «відкрито» доступні моделі, так і «закриті» моделі ШІ, доступ до яких можна отримати лише через API. У низці змагань з програмування на платформі Codeforces, DeepSeek випереджає інші моделі, зокрема Llama 3.1 405B від Meta, GPT-4o від OpenAI та Qwen 2.5 72B від Alibaba.