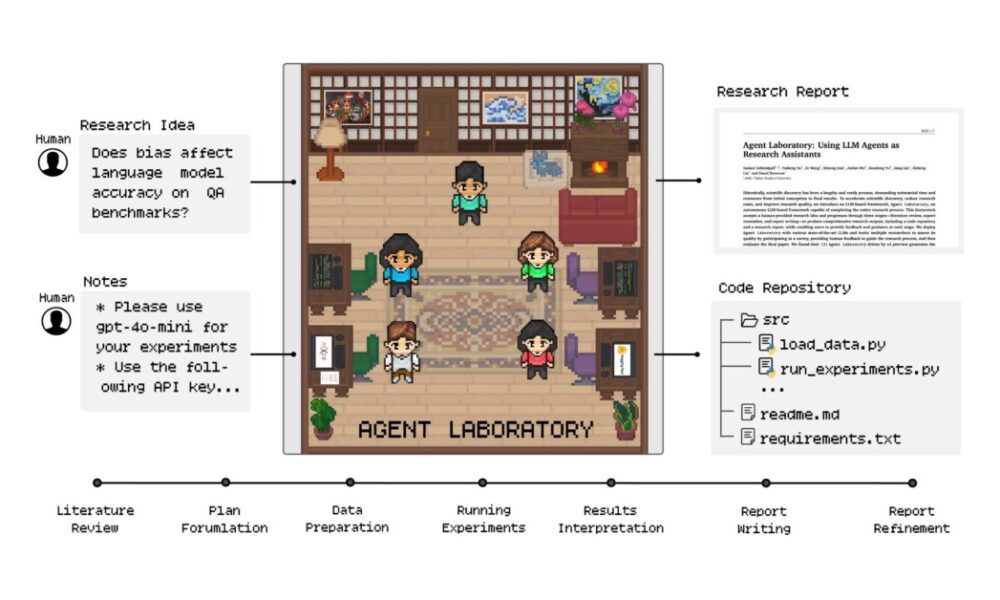
Поки всі дзижчать Агенти ШІ і автоматизації, AMD і Університет Джона Гопкінса працюють над покращенням того, як люди та ШІ співпрацюють у дослідженнях. Їхня нова структура з відкритим кодом, Агентська лабораторіяце повне переосмислення того, як можна прискорити наукові дослідження завдяки командній роботі людини та ШІ.
Після вивчення численних дослідницьких фреймворків ШІ, Agent Laboratory виділяється своїм практичним підходом. Замість того, щоб намагатися замінити людей-дослідників (як багато існуючих рішень), він зосереджується на посиленні їхніх можливостей, займаючись трудомісткими аспектами дослідження, утримуючи людей на місці водія.
Основна інновація тут проста, але потужна: Замість того, щоб проводити повністю автономні дослідження (які часто призводять до сумнівних результатів), Agent Laboratory створює віртуальну лабораторію, де кілька спеціалізованих агентів штучного інтелекту працюють разом, кожен з яких займається різними аспектами дослідницького процесу, залишаючись прив’язаним до вказівок людини.
Знищення віртуальної лабораторії
Подумайте про Agent Laboratory як про добре організовану дослідницьку групу, але з агентами ШІ, які виконують спеціальні ролі. Подібно до справжньої дослідницької лабораторії, кожен агент має певні обов’язки та досвід:
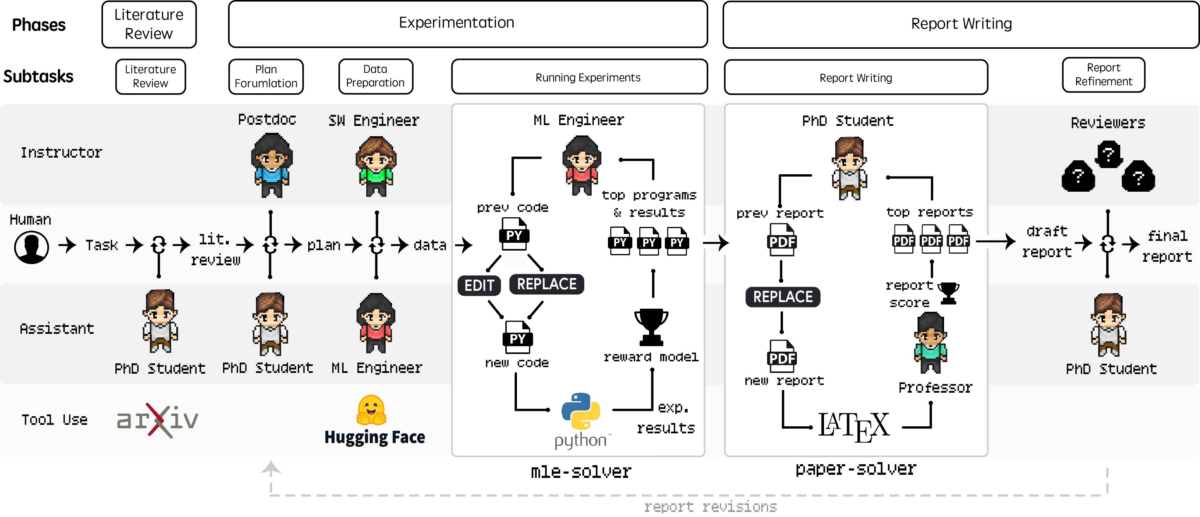
- Агент PhD займається оглядом літератури та плануванням досліджень
- Агенти Postdoc допомагають вдосконалювати експериментальні підходи
- Агенти ML Engineer займаються технічною реалізацією
- Агенти професора оцінюють результати досліджень
Що робить цю систему особливо цікавою, так це її робочий процес. На відміну від традиційних інструментів штучного інтелекту, які працюють ізольовано, Agent Laboratory створює середовище для спільної роботи, де ці агенти взаємодіють і спираються на роботу один одного.
Процес йде за природним прогресом дослідження:
- Огляд літератури: Агент PhD переглядає академічні статті за допомогою arXiv APIзбір та організація відповідних досліджень
- Формулювання плану: Докторські та постдокторські агенти об’єднуються для створення детальних планів досліджень
- Реалізація: Агенти ML Engineer пишуть і тестують код
- Аналіз і документація: Команда працює разом, щоб інтерпретувати результати та створювати вичерпні звіти
Але ось де це стає дійсно практичним: Структура є гнучкою щодо обчислень, тобто дослідники можуть розподіляти ресурси на основі свого доступу до обчислювальної потужності та бюджетних обмежень. Це робить його інструментом, розробленим для реальних дослідницьких середовищ.
Шмідгал та ін.
Людський фактор: де штучний інтелект зустрічається з досвідом
Хоча Agent Laboratory має вражаючі можливості автоматизації, справжня магія відбувається в тому, що вони називають «режимом другого пілота». У такій установці дослідники можуть надавати зворотній зв’язок на кожному етапі процесу, створюючи справжню співпрацю між людським досвідом і допомогою ШІ.
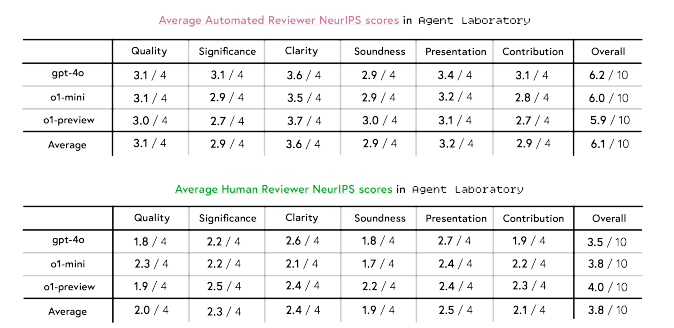
Дані відгуків другого пілота розкривають деякі переконливі ідеї. В автономному режимі документи, створені Agent Laboratory, отримали в середньому 3,8/10 в оцінках людьми. Але коли дослідники задіяли режим другого пілота, ці оцінки підскочили до 4,38/10. Що особливо цікаво, це те, де виявилися ці покращення – документи отримали значно вищі оцінки за чіткість (+0,23) і презентацію (+0,33).
Але ось перевірка реальності: навіть за участю людини ці роботи все одно отримали приблизно 1,45 бала нижче середнього прийнятого NeurIPS папір (який сидить на 5,85). Це не провал, але це важливе знання про те, як штучний інтелект і людський досвід повинні доповнювати один одного.
Оцінка показала ще щось захоплююче: Рецензенти зі штучним інтелектом постійно оцінювали статті приблизно на 2,3 бали вище, ніж люди. Ця прогалина підкреслює, чому людський нагляд залишається вирішальним в оцінці досліджень.
Шмідгал та ін.
Розбивка чисел
Що насправді важливо в дослідницькому середовищі? Вартість і продуктивність. Підхід Agent Laboratory до порівняння моделей показує деякі дивовижні переваги ефективності в цьому відношенні.
GPT-4o став чемпіоном за швидкістю, виконавши весь робочий процес лише за 1165,4 секунди – це в 3,2 раза швидше, ніж o1-mini, і в 5,3 раза швидше, ніж o1-preview. Але що ще важливіше, це те, що він коштує лише $2,33 за папір. Порівняно з попередніми автономними методами дослідження, які коштували близько 15 доларів США, ми очікуємо зниження витрат на 84%.
Перегляд продуктивності моделі:
- o1-preview отримав найвищий бал за корисність і ясність
- o1-mini досяг найкращих експериментальних показників якості
- GPT-4o відставав за показниками, але лідирував за економічною ефективністю
Реальні наслідки тут значні.
Тепер дослідники можуть вибрати свій підхід на основі своїх конкретних потреб:
- Потрібне швидке створення прототипів? GPT-4o забезпечує швидкість і економічність
- Пріоритет експериментальної якості? o1-mini може бути вашим найкращим вибором
- Шукаєте найвитонченіший результат? o1-preview показує перспективу
Ця гнучкість означає, що дослідницькі групи можуть адаптувати структуру до своїх ресурсів і вимог, а не замикатися на універсальному рішенні.
Нова глава в дослідженнях
Ознайомившись із можливостями та результатами Agent Laboratory, я переконаний, що ми спостерігаємо значні зміни в тому, як проводитимуться дослідження. Але це не розповідь про заміну, яка часто домінує в заголовках – це щось набагато більш тонке та потужне.
Хоча статті Agent Laboratory самі по собі ще не досягають найвищих стандартів конференцій, вони створюють нову парадигму для прискорення досліджень. Подумайте про це як про команду дослідників ШІ, які ніколи не сплять, кожен із яких спеціалізується на різних аспектах наукового процесу.
Наслідки для дослідників глибокі:
- Час, витрачений на перегляд літератури та базове кодування, можна було б перенаправити на творчі ідеї
- Дослідницькі ідеї, які могли бути відкладені через обмеження ресурсів, стають життєздатними
- Здатність швидко створювати прототипи та перевіряти гіпотези може призвести до швидших проривів
Поточні обмеження, як-от розбіжність між результатами штучного інтелекту та результатами перевірки людьми, є можливостями. Кожна ітерація цих систем наближає нас до більш складної дослідницької співпраці між людьми та ШІ.
Забігаючи наперед, я бачу три ключові події, які можуть змінити наукові відкриття:
- У міру того, як дослідники навчаться ефективно використовувати ці інструменти, з’являться більш складні моделі співпраці між людиною та ШІ
- Економія коштів і часу може демократизувати дослідження, дозволяючи невеликим лабораторіям і установам здійснювати більш амбітні проекти
- Можливості швидкого створення прототипів можуть призвести до більш експериментальних підходів у дослідженнях
Ключ до максимізації цього потенціалу? Розуміння того, що Agent Laboratory та подібні структури є інструментами для розширення, а не автоматизації. Майбутнє досліджень полягає не у виборі між людським досвідом і можливостями ШІ, а в пошуку інноваційних способів їх поєднання.

