
Велика мовна модель Claude 3 Opus від Anthropic вперше випередила GPT-4 від OpenAI на Chatbot Arena — популярному краудсорсинговому рейтингу, який використовується дослідниками ШІ для оцінки відносних можливостей мовних моделей ШІ. Що це означає для індустрії штучного інтелекту.
«Король помер. RIP GPT-4», — написав розробник програмного забезпечення Нік Добос в X (Twitter), порівнюючи GPT-4 Turbo і Claude 3 Opus, який поширюється в соціальних мережах. Про це повідомляє Ars Technica.
З моменту включення GPT-4 до Chatbot Arena приблизно 10 травня 2023 року (таблиця лідерів була запущена 3 травня того ж року), варіації GPT-4 незмінно займали верхні рядки рейтингу, тож її поразка на Арені — помітний момент у відносно короткій історії мовних моделей штучного інтелекту. Одна з менших моделей Anthropic, Haiku, також привертає увагу своїми показниками в таблиці лідерів.
«Вперше найкращі доступні моделі — Opus для складних завдань, Haiku за вартістю та ефективністю — від постачальника, який не є OpenAI. Це обнадіює — ми всі виграємо від різноманітності провідних постачальників в цій галузі. Але GPT-4 вже понад рік, і цей рік знадобився для того, щоб хтось інший зміг його наздогнати», — сказав незалежний дослідник ШІ Саймон Віллісон.
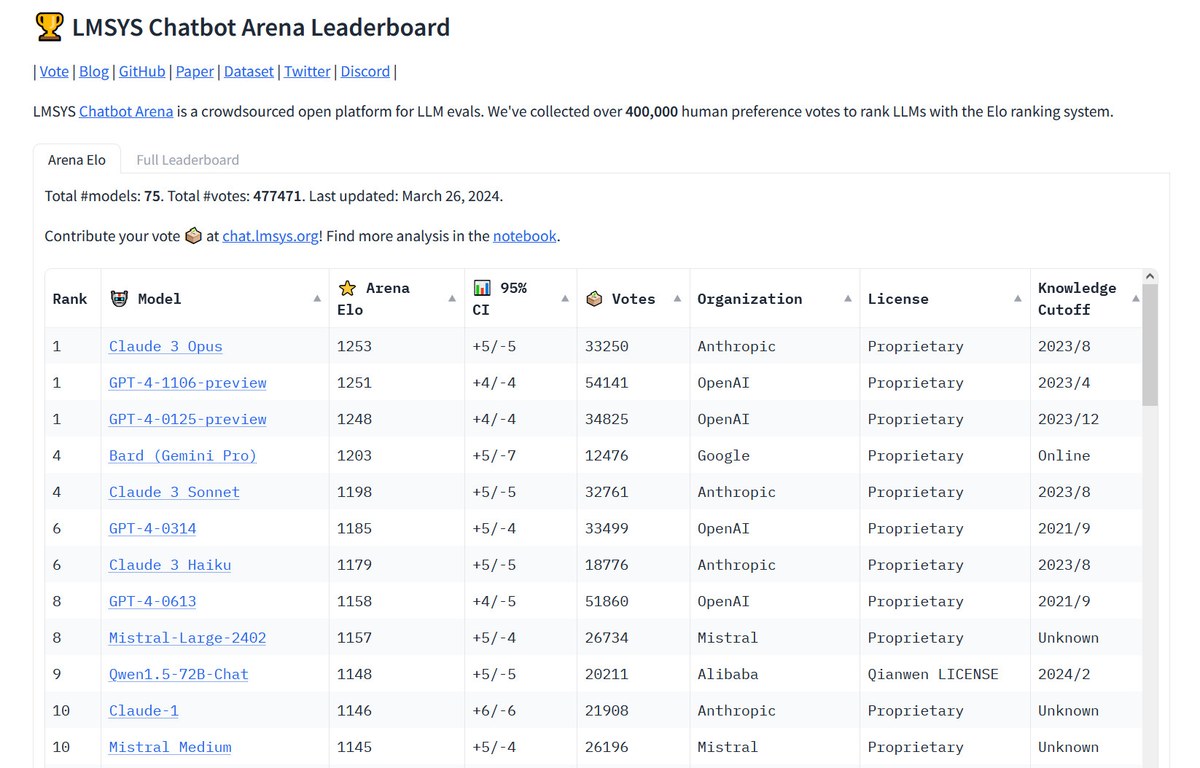
Як працює Chatbot Arena
Chatbot Arena управляється Організацією великих модельних систем (LMSYS ORG), дослідницькою організацією, що займається відкритими моделями, яка працює в рамках співпраці між студентами та викладачами Каліфорнійського університету в Берклі, Університету Сан-Дієго та Університету Карнегі-Меллона.
Chatbot Arena представляє користувачеві, який заходить на сайт, поле для введення чату і два вікна, що показують результати роботи двох анонімних великих мовних моделей ШІ. Завдання користувача полягає в тому, щоб оцінити, яка відповідь є кращою на основі будь-яких критеріїв, які користувач вважає найбільш прийнятними. Завдяки тисячам таких суб’єктивних порівнянь Chatbot Arena обчислює «найкращі» моделі в сукупності та заповнює таблицю лідерів, оновлюючи її з часом.
Chatbot Arena важлива для дослідників, оскільки вони часто розчаровуються, намагаючись виміряти ефективність чат-ботів зі штучним інтелектом, чиї результати важко піддаються кількісній оцінці.
Провісники перемоги Claude 3 почали з’являтися ще кілька тижнів тому. «Щойно мав довгу сесію кодування з Claude 3 Opus, і він абсолютно розтрощив GPT-4. Не думаю, що стандартні бенчмарки справедливо оцінюють цю модель», — написав розробник програмного забезпечення для ШІ Антон Бакай 19 березня.
Наразі в рейтингу є чотири різні версії GPT-4, які являють собою інкрементні оновлення LLM, які заморожуються в часі, оскільки кожна з них має унікальний стиль виводу, і деякі розробники, які використовують їх з API OpenAI, потребують узгодженості, щоб їхні програми, побудовані на основі вихідних даних GPT-4, не зламалися.
Проте, навіть з чотирма моделями GPT-4 у списку лідерів, моделі Claude 3 від Anthropic послідовно підіймаються вгору з моменту їхнього випуску на початку цього місяця. Успіх Claude 3 серед асистентів зі штучним інтелектом вже призвів до того, що деякі користувачі великих мовних моделей замінили ChatGPT у своєму повсякденному робочому процесі, що потенційно може поглинути частку ринку ChatGPT.
Схожий за можливостями Gemini Advanced від Google також набирає обертів у сфері ШІ-помічників. Це може змусити OpenAI насторожитися, але в довгостроковій перспективі компанія готує нові моделі. Очікується, що вона випустить новий великий наступник GPT-4 Turbo (під назвою GPT-4.5 або GPT-5) десь цього року, можливо, влітку. Конкуренція на ринку ШІ все більше загострюється, і схоже, що рейтинг лідерів Chatbot Arena в найближчі місяці та роки ставатиме дедалі цікавішим.


