
Senior Data Scientist Макс Вульф з видання BuzzFeed перевірив одну цікаву гіпотезу, навіяну вірусним трендом з 2023. Він з’ясував, що буде, якщо ШІ-чатботу дати завдання й кілька разів поспіль попросити покращити результат.
У листопаді 2023 року, після того, як OpenAI додав можливість для ChatGPT генерувати зображення з DALL-E 3 у вебінтерфейсі ChatGPT, з’явився короткочасний мем, коли користувачі давали ШІ базове зображення і продовжували просити модель «зробити його більш X», де X може бути чим завгодно.
Макс Вульф нагадує, що цей тренд швидко вичерпався, а всі зображення врешті-решт зводилися до чогось космічного, незалежно від початкового зображення і підказки. За його словами, хоча цей тренд і був спровокований помилкою штучного інтелекту, з наукового погляду цікаво, що така розпливчаста підказка мала певний вплив на кінцеве зображення.
«Що б сталося, якби ми спробували застосувати подібну техніку з кодом? Код, згенерований за допомогою LLM, навряд чи буде поганим (хоча й не виключено), оскільки він слідує суворим правилам, і, на відміну від творчих результатів, таких як зображення, якість коду можна виміряти більш об’єктивно», — запитує Вульф.
Йому стало цікаво, якщо код дійсно можна покращити просто за допомогою ітеративних підказок, наприклад, попросити велику мовну модель «зробити код кращим», що станеться, якщо ітерації над кодом будуть занадто частими? Чи з’явиться еквівалент «космічно» написаного коду?
Як ШІ покращив свій код завдяки промпту
Для експерименту він обрав чатбот Claude 3.5 Sonnet від Anthropic. За словами Макса Вульфа, він має «неймовірну швидкість виконання всіх типів підказок», особливо промптів із кодування. Крім того, бенчмарки з кодування також віддають перевагу Claude 3.5 Sonnet порівняно з GPT-4o.
Для експерименту Claude 3.5 Sonnet отримав завдання з типової співбесіди для програмістів-початківців на Python. Воно було достатньо простим, але унікальним, щоб ШІ не списав вже готове рішення з інтернету, а також таким, що мало простір для покращення.
Як бенчмарк покращення Вульф обрав швидкість виконання коду із завдання. На його Macbook Pro M3 Pro цей код виконувався в середньому за 657 мілісекунд. Всього він зробив 5 ітерацій з проханням покращити код.
Висновки з експерименту Вульфа
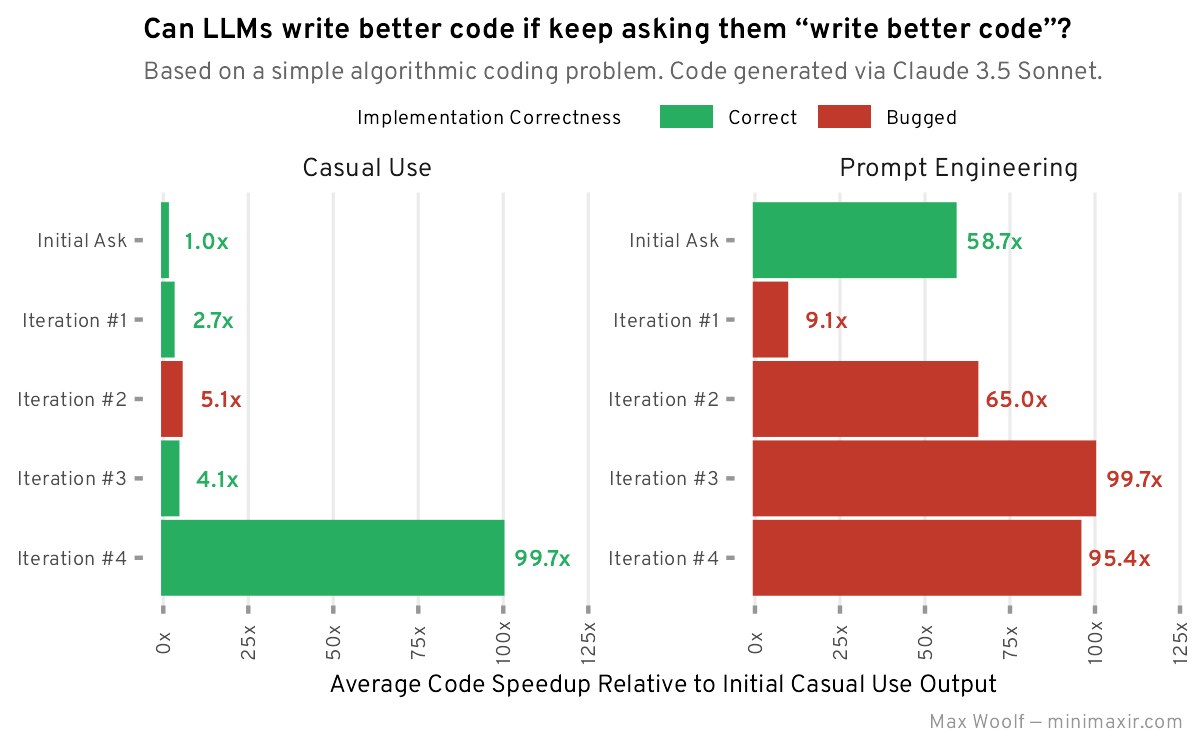
«Загалом, прохання до LLM „написати кращий код“ дійсно робить код кращим, залежно від того, що ви розумієте під „кращим“. Завдяки використанню загальних ітеративних підказок, код об’єктивно покращився порівняно з базовими прикладами, як з погляду додаткових функцій, так і швидкості», — зробив висновок Макс Вульф.
За його словами, промпт-інжиніринг покращував продуктивність коду набагато швидше і послідовніше, але з більшою ймовірністю призводила до появи малопомітних багів, оскільки великі мовні моделі не оптимізовані для генерації високопродуктивного коду.
«Як і при будь-якому використанні LLM, ваш результат може бути різним, і врешті-решт для виправлення неминучих проблем знадобиться людський підхід, незалежно від того, як часто апологети ШІ називають LLM магією», — зазначив Вульф. Він додав, що охочі можуть переглянути код з експерименту, включно зі скриптами бенчмаркінгу та кодом візуалізації даних, на GitHub.
«Звичайно, ці LLM не замінять інженерів-програмістів найближчим часом, тому що для того, щоб розпізнати, що насправді є гарною ідеєю, потрібна сильна інженерна підготовка, а також інші обмеження, які є специфічними для конкретного домену. Навіть зважаючи на кількість коду, доступного в Інтернеті, LLM не можуть відрізнити середній код від хорошого, високопродуктивного коду без сторонньої допомоги», — попередив Senior Data Scientist.
Український експерт із піару, комунікацій і застосування технологій ШІ Олексій Мінаков зазначив, що цей експеримент вказує на важливість промпт-інжинірингу.
«Перша відповідь навряд буде оптимальною, тому що моделі тяжіють до надання середнього результату (якщо детальніше, то моделі прогнозування наступного токена навчаються максимізувати ймовірність прогнозування наступного токена над величезними партіями входів, і в результаті вони оптимізують для середніх входів і виходів)», — написав Мінаков у своєму Facebook.
Він закликав «не лінуватися продовжувати взаємодію з ChatGPT, Gemini чи Claude» після першої згенерованої відповіді.
За словами Олександра Краковецького, CEO ІТ-компаній DevRain та DonorUA, автора книжки «ChatGPT, DALL·E, Midjourney: Як генеративний штучний інтелект змінює світ», ключовий висновок експерименту Вульфа полягає в тому, що «хоча LLM мають значний потенціал у генерації та оптимізації коду, їхня робота потребує обов’язкового людського контролю».
«Модель може запропонувати ефективні ідеї або покращення, але остаточну перевірку та тестування коду має виконувати розробник. Це підкреслює важливість розуміння того, що LLM є інструментом, а не заміною для програмістів», — додав він.


