
18 жовтня 2017 року, рівно 7 років тому, DeepMind, дочірня компанія Google, оголосила про випуск розвинутої версії своєї революційної ШІ-системи AlphaGo — AlphaGo Zero, демонструючи значний потенціал машинного навчання для виконання складних завдань. Ці дві системи ШІ для таких ігор, як ГО, сьогі та шахи, що здатні перемагати чемпіонів світу, призвели до сплеску інтересу до штучного інтелекту та його потенційних застосувань у різних сферах.
Пройшли роки, а принципи, що лежать в основі AlphaGo, продовжують застосовувати для розв’язання реальних проблем: створення ліків, побудови військових стратегій, розробки останніх поколінь ШІ та навіть для квантових комп’ютерів. Творці розробки на основі AlphaGo отримали Нобелівську премію, Gemini теж має тісний зв’язок із цією програмою, а для Китаю ця ШІ-система стала справжнім бустером для розвитку штучного інтелекту в країні.
Зміст
AlphaGo — ШІ-система, яка перемогла чемпіона світу з найскладнішої гри ГО та надихнула нову еру штучного інтелекту

Стародавня гра ГО
ГО — це стародавня китайська настільна гра, якій приблизно 3000 років. Довгий час вона вважалася великим викликом для ШІ.
Гра складається з квадратної дошки із сіткою 19X19, на якій гравці по черзі розміщують чорні або білі камені. Перемагає той, хто займе більше території. На перший погляд, це нескладно, але насправді вона в рази складніша за шахи — з приголомшливими 10 в степені 170 можливими конфігураціями дошки. Це більше, ніж кількість атомів у відомому Всесвіті.
У жовтні 2015 року AlphaGo зіграла свою першу гру з триразовим чемпіоном Європи Фан Хуя. ШІ-система виграла перший в історії матч із професіоналом із Го: рахунок — 5:0.
У березні 2016 року AlphaGo перемогла з рахунком 4:1 легендарного гравця Го Лі Седола — володаря 18 світових титулів, якого багато хто вважає найвидатнішим гравцем того десятиліття. Цей матч спостерігали понад 200 млн людей по всьому світу.

Як працює ШІ-система AlphaGo
Розробники DeepMind, дочірньої компанії Google, створили AlphaGo у 2015 році. Ця ШІ-система поєднує глибокі нейронні мережі з розширеними алгоритмами пошуку.
Одна нейронна мережа — відома як «мережа політики» — обирає наступний хід гри. Інша нейронна мережа — «мережа цінностей» — прогнозує переможця гри.
Спочатку AlphaGo брала участь у численних аматорських іграх ГО, щоб система могла дізнатися, як люди грають у гру. Вона «навчалася» на основі 30 млн ходів, зроблених гравцями-людьми.
Потім вона грала проти різних версій себе тисячі разів, щоразу навчаючись на своїх помилках — метод, відомий як навчання з підкріпленням (RL). Саме завдяки цьому методу машини можуть навчитися самостійно вирішувати неймовірно складні проблеми просто шляхом проб і помилок. І саме навчання з підкріпленням буде в майбутньому використовуватися в наступних системах ШІ, наприклад Gemini, про що розкажемо нижче.
Система AlphaGo має наступниць: AlphaZero, MuZero та AlphaDev
18 жовтня 2017 року DeepMind анонсував першу поліпшену версію AlphaGo — AlphaZero, яка використовує ще складніші алгоритми навчання.
Вона відрізняється від своєї попередниці тим, що вона не використовувала зроблених людьми ходів під час навчання. Натомість вона навчалася, граючи сама проти себе.
AlphaZero не тільки змогла перемогти попередницю AlphaGo, але за допомогою способу, відомого як «перехідне навчання», вона також здолала найкращі у своєму класі комп’ютери із шахів і гри в сьогі (японські шахи).
AlphaZero опанувала шахи всього за 9 годин. Сьоґі за 12 годин. А Го — за 13 днів. У кожній грі вона навчилася грати з унікальним і творчим стилем.
MuZero йде на крок далі, ніж AlphaZero.
Без пояснення правил гри MuZero досягає рівня AlphaZero в го, шахах і сьоґі, а також вчиться опановувати набір візуально складних ігор Atari.
Для цього вивчає модель свого оточення, наприклад, гру, у яку грає. Потім MuZero використовує цю модель для планування найкращого способу дій.
Улітку 2023 року DeepMind представив AlphaDev, базується на AlphaZero, яка може розробляти високооптимізовані алгоритми сортування без прикладів людського коду. Система націлена на досягнення високої ефективності при забезпеченні безпомилкового виконання.
Завдяки підвищеній ефективності ці нові алгоритми сортування можуть революціонізувати багато сфер, наприклад управління базами даних, функціонування пошукових систем і платформ онлайн-продажів.
Вплив AlphaGo, AlphaZero та MuZero на ШІ
Обидві ШІ-системи є важливими кроками до створення загальних і потужних систем ШІ, які можуть вирішувати широкий спектр реальних проблем.
Наприклад, нові версії AlphaZero відкрили швидші алгоритми сортування, хешування та множення матриць, які зараз використовуються трильйони разів на день у всьому світі.
Тим часом MuZero допомагає ефективніше стискати відео на YouTube, зменшуючи інтернет-трафік і щодня ефективніше надаючи мільйони годин вмісту. Це означає кращий доступ до інформації та розваг для мільярдів людей.
Усі три ШІ-системи мають глибокий і довготривалий вплив на здатність ШІ вирішувати складні завдання та пропонувати інноваційні рішення:
- Їхня здатність навчатися та стратегічно планувати забезпечує основу для вирішення завдань оптимізації, таких як розподіл ресурсів, планування та логістика.
- Можливості самонавчання можна адаптувати для покращення процесів прийняття рішень у динамічних середовищах для підвищення продуктивності та ефективності роботизованих систем.
- Їхня адаптивна природа може бути використана в індивідуальному навчанні й освіті. Адаптуючи ці підходи, ми можна використовувати їх для персоналізованих рекомендацій, адаптивного репетиторства, забезпечення зворотного зв’язку, покращення навчального процесу й оптимізації освітніх результатів.
Після перемоги AlphaGo викликала інтерес у військових, особливо у стратегів
Перемога AlphaGo стала бустером для розвитку ШІ у Китаї.
Наступного місяця після перемоги AlphaGo над чемпіоном світу з Го у березні 2016 року, Академія військових наук Китаю провела семінар, присвячений наслідкам цього матчу. «Для китайських військових стратегів одним з уроків, винесених із перемог AlphaGo, став той факт, що ШІ може створювати тактику і стратегії, що перевершують тактику та стратегії людини-гравця в грі, яку можна порівняти з військовою грою», — сказала Ельза Канія, експерт із китайських військових інновацій.
Через два місяці Керівництво Комуністичної партії Китаю (КПК) оприлюднила свій амбітний план розвитку штучного інтелекту нового покоління.
Успіх AlphaGo, викликав інтерес у військових стратегів, які вважають, що інтеграція штучного інтелекту типу AlphaGo у військове планування може змінити процес прийняття стратегічних рішень, поєднуючи точність і креативність для високої ефективності.
Використовуючи ті самі загальні принципи, які допомагають перемагати AlphaZero, штучний інтелект може визначати моделі поведінки, які навіть супротивник не планував і не помічав, а потім рекомендувати методи протидії їм.
В основі Gemini лежать технології від AlphaGo
Gemini — це мультимодальна велика мовна модель Google, вперше представлена у травні 2023 році, яку поступово інтегрують в усі продукти компанії. Вона об’єднує потужність AlphaGo з іншими технологіями LLM від Google і DeepMind.
До випуску Gemini генеральний директор DeepMind Деміс Хассабіс сказав в інтерв’ю Wired: «На високому рівні ви можете думати про Gemini як об’єднання сильних сторін систем типу AlphaGo з дивовижними мовними можливостями великих моделей».
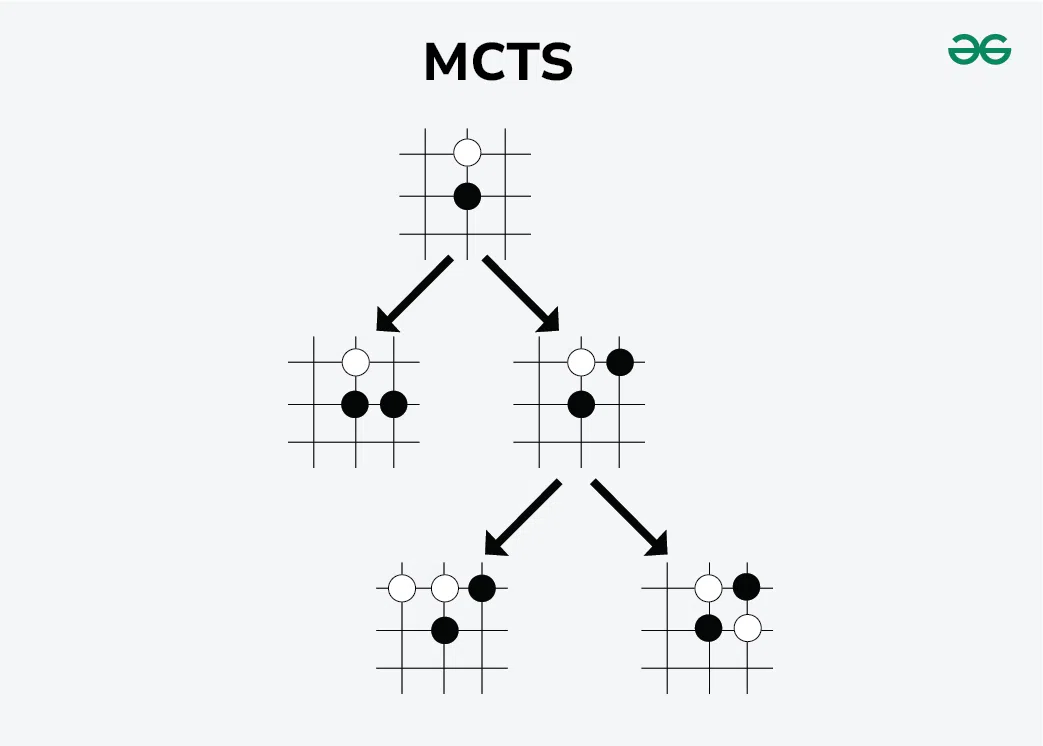
Завдяки використанню методів AlphaGo, Gemini має просунуті можливості в розв’язанні проблем і плануванні. Один із них — це навчання з підкріпленням, коли ШІ навчається шляхом повторення дій і отримання винагороди за правильні дії. Інший — пошук дерева за методом Монте-Карло (MCTS). Це пошуковий алгоритм для процесів прийняття рішень, який досліджує можливі ходи в грі, моделюючи безліч потенційних майбутніх станів гри, щоб визначити найбільш перспективний хід.
Хімія
Яскравим прикладом впливу AlphaGo на хімію є розробка AlphaFold2 від DeepMind — ШІ, який точно прогнозує структуру білків. Цю технологію створили Деміс Хассабіс, співзасновник і генеральний директор DeepMind, та його колега Джон Джампер, за що вони отримали нещодавно Нобелівську премію з хімії.
Відкриття ліків. На основі архітектури AlphaGo алгоритми ШІ можуть аналізувати величезні хімічні бази даних, прогнозувати молекулярні властивості та визначати потенційні варіанти ліків з підвищеною ефективністю та точністю. Це прискорює розробку ліків, що потенційно може призвести до прориву в лікуванні таких захворювань, як рак і хвороба Альцгеймера.
Матеріалознавство. ШІ може допомогти в розробці нових матеріалів з потрібними властивостями, такими як міцність, провідність або термостійкість. Моделюючи та прогнозуючи поведінку молекул і атомів, ШІ може допомогти дослідникам у відкритті та синтезі матеріалів, які можна застосовувати в електроніці, накопичувачах енергії й інших галузях. Це може призвести до розробки легших, міцніших і стійкіших матеріалів для різних застосувань.
Оптимізація хімічних реакцій. Аналізуючи умови реакції та прогнозуючи результати, ШІ може допомогти хімікам розробити більш ефективні та стійкі шляхи синтезу, зменшуючи кількість відходів і мінімізуючи вплив на навколишнє середовище. Це сприяє ініціативам екологічної хімії та допомагає розробляти екологічно чисті хімічні процеси.
Медицина
Один із прикладів у сфері медицини, окрім ліків, технологія AlphaGo була використана Національною службою охорони здоров’я Великої Британії для розробки додатка Streams, який відстежує пацієнтів із захворюваннями нирок і сповіщає лікарів у разі гострого пошкодження нирок.
Квантові обчислення
Алгоритм AlphaZero може допомогти розкрити потужність і потенціал квантових обчислень. Такого висновку дійшли дослідники Орхуського університету в Данії у 2020 році. Команда використала алгоритм AlphaZero для керування квантовим комп’ютером.
Вони вважають перевірені в іграх можливості самонавчання AlphaZero можуть дозволити квантовому комп’ютеру систематично обходити обмеження, а саме залежність від хороших початкових припущень.
Команда виявила, що система досягла найкращих результатів, коли вони поєднали алгоритм AlphaZero зі спеціалізованим алгоритмом квантової оптимізації.
Намагаючись прискорити розвиток у цій галузі, дослідницька група оприлюднила код, і вони були здивовані таким інтересом. «Протягом кількох годин зі мною зв’язалися великі технологічні компанії з квантовими лабораторіями та міжнародні провідні університети, щоб налагодити майбутню співпрацю», — сказав один з дослідників Джейкоб Шерсон.
Спадщина AlphaGo продовжує надихати дослідників та розробників, які прагнуть розширити межі штучного інтелекту та досліджувати нові способи використання потужності машинного навчання та нейронних мереж для покращення людства.


